

Début mars 2021, une énorme panne web a fait tomber un certain nombre de sites Web majeurs en France. Un incendie a complètement détruit l’un des quatre « datacenters » d’OVHcloud et touché partiellement le deuxième data center. Entre 12 000 et 16 000 clients (parmi ses 1,6 million de clients) ont été touchés, et de nombreux sites Web étaient temporairement indisponibles.
Protéger votre entreprise d’une panne web
Selon diverses sources médiatiques et une information confirmé par la société OVH, le problème est due à un incendie. Dans un Tweet, Octave Klaba DG de Ovh Cloud annonce une reprise partielle des services à partir de lundi 15 mars. Soit 5 jours après le sinistre. Certaines société qui n’avaient pas prévu de solution de secours se sont retrouvé plusieurs semaines sans solutions viable. Avec à la clé des services essentiel hors ligne, une gigantesque panne web en Europe.
Alors quelles solutions contre les pannes web pour votre entreprise ?
Avoir une infrastructure stable est essentielle à une entreprise pereine. En raison des changements fréquents, la maintenance et la sécurité de votre site web sont des éléments clés qui vous permettent de vous concentrer sur votre business. Voici comment protéger votre entreprise en trois étapes au cas où cela se reproduirait.
Qui héberge les sites dans le monde ?
D’après des chiffre de Statista de 2017 et Selon les données du site hostadvice.com, le français OVH est le cinquième hébergeur Web au monde. En fait, il détient une part de marché de 2,12 %.
Sans surprise, à l’exception de 1 & 1, les hébergeurs les plus importants sont sous drapeau américain, se classant deuxième, juste derrière GoDaddy et devant Amazon Web Services. En plus d’eux, il y a trois autres hôtes allemands.
Au total, ce sont dix sociétés qui hébergent près d’un quart des sites Internet dans le monde.
 Vous trouverez plus d’infographie sur Statista
Vous trouverez plus d’infographie sur Statista
1. Mettre en œuvre une infrastructure HA (Haute Disponibilité) dans plusieurs régions
Une architecture de cluster à haute disponibilité se compose de quatre composants clés :
1. Équilibrage de charge
Un système hautement disponible doit disposer d’un mécanisme d’équilibrage de charge bien conçu et préconçu pour répartir les demandes des clients entre les nœuds du cluster. Le mécanisme d’équilibrage de charge doit spécifier le processus de basculement exact lorsqu’un nœud échoue.
2. Évolutivité des données
Un système hautement disponible doit tenir compte de l’évolutivité de la base de données ou de l’unité de stockage sur disque. Deux options populaires pour l’évolutivité des données utilisent une base de données centralisée et la rendent hautement disponible via la réplication ou le partitionnement ; ou pour garantir qu’une seule instance d’application peut gérer son propre magasin de données.
3. Diversité géographique
Dans l’environnement informatique d’aujourd’hui, en particulier lorsque la technologie cloud est si disponible, il est essentiel de distribuer des clusters à haute disponibilité sur plusieurs emplacements géographiques. Cela garantit que le service ou l’application est résilient aux sinistres qui affectent un emplacement physique, car il peut basculer vers un nœud dans un autre emplacement physique. De nombreuses entreprise n’ayant pas anticipé ce risque on eu de sérieux problème lors de l’incendie chez l’hébergeur OVH en mars 2021.
4. Sauvegarde et récupération
L’architecture à haute disponibilité est toujours sujette aux erreurs, provoquant l’échec de l’ensemble du service. Si cela se produit, le système doit disposer d’une stratégie de sauvegarde et de restauration afin que l’ensemble du système puisse être restauré dans un délai de restauration prédéfini (RTO).
La règle de sauvegarde standard appelée « 3-2-1 » stipule que vous devez conserver trois copies des données sur deux types de supports dans un même emplacement géographique. Avec Cloud, nous pouvons ajouter des emplacements géographiques supplémentaires, de sorte que le modèle peut être modifié en 3-2-x-où x est le nombre d’emplacements géographiques sauvegardés.
Effectuer régulièrement des tests de résistance sur l’infrastructure pour faire face aux défaillances et attaques potentielles

L’infrastructure de chaque entreprise change régulièrement. Cela signifie non seulement démarrer de nouveaux serveurs, mais aussi acquérir de nouveaux utilisateurs, établir de nouvelles connexions et mettre en œuvre de nouvelles méthodes d’authentification. Chaque nouveau composant augmente la surface d’attaque et augmente le nombre d’attaques potentielles, telles que DDoS, injection de code et autres exploits. s attaque. Infrastructure. Par conséquent, la maintenance de la sécurité est une option qui ne peut être ignorée.
- Tests de pénétration interne : Ils se concentrent sur la détermination d’une surface d’attaque interne – en contournant le contrôle d’accès au réseau, en compromettant les serveurs internes et en augmentant les privilèges. Un attaquant peut être une personne anonyme ou un employé.
- Tests de pénétration externe : Ils se concentrent sur la détermination d’une surface d’attaque externe – la configuration DNS publique, tous les hôtes exposés à Internet et les services publiés sur ces serveurs. Ici, un attaquant vient de l’extérieur.
La sécurité de l’infrastructure est tout aussi importante que la sécurité des applications Web. Sécuriser les deux nous donne un sentiment de sécurité
La défaillance de l’infrastructure (panne) est principalement testée en tant que test de basculement. Il s’agit d’une technique qui vérifie la capacité du système à passer rapidement d’une ressource à une autre (par exemple, machine virtuelle, base de données) et à être entièrement prêt à gérer les données sans perte de données ou de disponibilité.
Dans un cas typique, un test de sécurité de l’infrastructure est effectué selon les étapes suivantes :
- Acquérir des ressources qui seront testées.
- Modélisation des menaces – analyse de sécurité visant à déterminer les méthodes d’attaque possibles et les conséquences les plus importantes.
- Établir les priorités , les exclusions et les dépendances.
- Réalisation d’essais . Un client est informé en permanence des principales vulnérabilités identifiées.
- Reporting et analyse .
- Consultations sur la façon de supprimer les vulnérabilités.
- Vérification de la bonne suppression des vulnérabilités.
Créer des copies de sauvegarde selon les bonnes pratiques et vérifier régulièrement leur intégrité
Assurez-vous que vos données sont stockées à deux endroits physique différents assez éloignés. Parmi les options, il existe des options redondantes. « Au lieu de stocker les informations de votre site sur un seul serveur, nous les stockons sur un second serveur, qui n’est pas au même endroit. Le problème avec l’incendie d’OVH en mars, c’est que certains serveurs sont juste redondants sur le même serveur. Restent. «
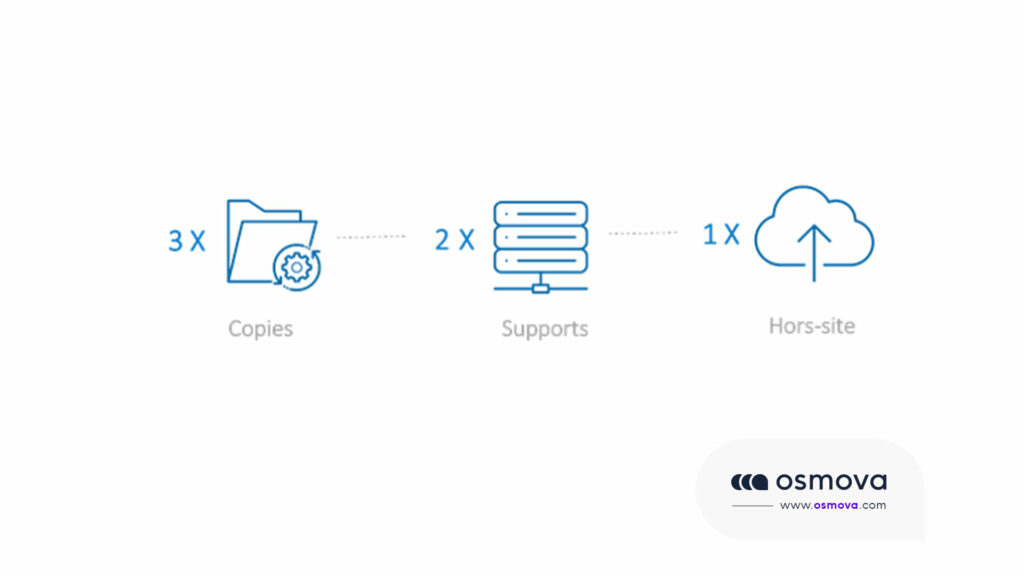
La stratégie de sauvegarde 3 – 2 – 1 indique simplement que vous devez avoir 3 copies de vos données (vos données de production et 2 copies de sauvegarde ) sur deux supports différents (disque et bande) avec une copie hors site pour la reprise après sinistre.
5 bonnes pratiques pour la sauvegarde basée sur le cloud :
- Comprendre les objectifs de récupération . Sans objectifs de récupération , il est difficile de créer une stratégie de sauvegarde cloud efficace .
- Redondance redondance. Ce n’est jamais trop .
- Tenez compte à la fois de la perte de données et des temps d’arrêt. L’objectif de point de récupération (RPO) et l’objectif de temps de récupération (RTO) sont deux des paramètres les plus importants d’un plan de récupération après sinistre ou de protection des données.
- Pensez aux systèmes et aux catégories de données .
- Envisagez d’utiliser un cloud de récupération si vous utilisez des solutions sur site .
En résumé contre une panne web et pour maintenir la sécurité et la disponibilité des données les plus élevées des éléments les plus importants de votre infrastructure, vous devez répondre à un certain nombre d’exigences.
Vous pouvez en présenter quelques-uns vous-même tout de suite en utilisant un outil de monitoring de site web. Une autre option pour assurer la plus haute sécurité et disponibilité consiste à confier la mise en œuvre de toutes les mesures mentionnées ci-dessus à des spécialistes.
Petits détails de base à considérer
Les précautions d’usage doivent être prises pour protéger au mieux l’entreprise et ses données. Ce sont de petits éléments de base, mais ils peuvent faire la différence.
Tout d’abord, vous devez être particulièrement prudent lorsque vous choisissez des mots de passe pour protéger le contenu commercial sensible (tels que les comptes bancaires de l’entreprise, les e-mails d’entreprise ou les données client). La précaution est d’éviter les anniversaires ou les derniers mots à la mode. La CNIL (Commission Nationale de l’Informatique et des Libertés) recommande de choisir un mot de passe composé d’au moins 12 caractères, mélangeant majuscules, minuscules, chiffres et caractères spéciaux.
Il existe une série de solutions et d’outils différents pour résoudre ce problème, comme les pare-feu de nouvelle génération qui détecte les menaces dans les applications collaboratives ou utilise des règles précises pour gérer le trafic Internet, et même bloque les logiciels malveillants, anti-malware et anti -ransomware. Alors ne laisser pas une panne web vous surprendre et ruiner les effort que vous mis dans la création de votre entreprise.
Qu’est-ce qu’un Plan de Reprise d’Activité (PRA) ?
Un protocole PRA est mis en œuvre dans l’entreprise pour vous garantir l’accès à votre système informatique afin que vos activités ne cessent de fonctionner.
En particulier, il est nécessaire de choisir et d’installer les équipements nécessaires. Celui-ci doit pouvoir prendre en charge toutes les tâches de l’élément critique qui a échoué (comme une panne de courant ou une cyberattaque).
Le PRA peut réduire les effets négatifs des événements rencontrés au cours des activités de votre entreprise. Ils peuvent évidemment gérer n’importe quelle crise en cas de panne de votre système informatique, quelle qu’en soit la raison.
Afin de réduire l’impact du sinistre, le protocole peut utiliser des solutions de redémarrage différentes. Vous pouvez choisir de redémarrer à chaud.
Il s’agit de redémarrer rapidement le serveur de secours en utilisant une copie des données de votre site.
Au contraire, le redémarrage à froid repose sur la restauration progressive de l’application et active le système de sauvegarde en fonction des données de la dernière sauvegarde.
Il est recommandé de faire appel à un prestataire informatique spécialisé dans ce domaine pour s’assurer de la validité de protocoles.